Research Interests
Work Lines
Our reasearch group studies the following areas:
- Solution to linear algebra problems on current high performance processors, hardware accelerators (GPUs and FPGAs), and parallel systems (multicore processors and clusters)
- Optimisation and tuning of codes and software packages for scientific and engineering applications
- Hardware-software codesign, computation and reconfigurable architectures
- Energy-aware computing, approximate computing and fault tolerance
- High performance computing for machine learning techniques and deep neural networks
Research Interests
Numerical Libraries
PI: José I. Aliaga, Sandra Catalán y Gregorio Quintana-Ortí.
From the beginning, the main research objective of the HPC&A members has been to improve the parallel implementation of numerical libraries. These developments had to maintain the numerical stability of the computations while reducing their execution time. Later, energy efficiency was added to the requirements of real-world implementations due to the increase in computer power consumption. In addition, these three goals (accuracy, performance and efficiency) had to be maintained in different architectures, from algorithms implemented on FPGAs to clusters of multicores equipped with accelerators as GPUs.
Proper use of the memory hierarchy is fundamental to reducing execution time. Some related decisions are deciding what data to store in registers and how to access the data to reduce cache misses. Compilers can help with some of these, but usually they require the cooperation of the programmer. Developing algorithms by blocks is one of the most common alternatives for reducing memory traffic. If the data is larger than local memory, it must be stored in external memory, and Out-Of-Core (OOC) algorithms must be used to reduce the cost of accessing the external memory. For GPU programming, some changes to the criteria are required, as appropriate memory access requires memory coalescing, whereas OOC programming needs main memory to be used as secondary memory.
In many cases, the theoretically fastest and most stable algorithm to solve a problem is mainly sequential, so its parallel implementation needs to choose an alternative stable algorithm. In the case where the parallelization reduces the stability of the implementation, the combination of direct and iterative algorithms can solve the problem. This combination can also mix different floating-point formats (double, single and half), which reduces memory access and then execution time.
In other cases, the same results must be obtained in each execution, regardless of the number of threads/processes used. This requires the management of specific floating-point formats to ensure the reproducibility of the executions. This usually increases the cost of execution, so parallelization of the algorithms is welcome, although some additional special techniques have to be applied.
Energy efficiency can be achieved by accelerating code execution using some of the above solutions. However, other techniques can be used to optimize energy efficiency. For example, if the features of a computation prevent it from reaching the maximum performance of a CPU, because it is memory bound, adjusting its frequency can maintain performance while reducing energy consumption.
Currently, our main research topics are the following:
- Mixed precision and Transprecision computing for sparse matrices on GPUs (included in GinkGo library [https://github.com/ginkgo-project/ginkgo]).
- Reproducibility for sparse matrices
- Thread malleability in numerical libraries, such as BLIS [https://github.com/flame/blis]
- Generation of high quality CT images
- High performance computing for solving quantum computing problems
- High performance computing for professional sports teams
MPI malleability
PI: José I. Aliaga y Maribel Castillo.
Process malleability in MPI can be defined as the ability of a distributed MPI parallel job to change the number of processes on–the–fly without stopping its execution, reallocating the compute resources originally assigned to the job, and without storing application data to disk.
The benefits of its use can be analyzed from two different points of view. For each individual application, the benefit can come from the increase of its particular performance when the job gets more resources, while for the global system, the benefit can come from the increase in throughput with the reduction of the makespan.
Malleability requires applications to create a reconfiguration point which all processes call to perform the resize. During the reconfiguration point the following four stages are performed:
-
- Resource reallocation
- Process Management
- Data redistribution
- Resuming execution
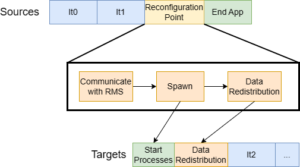
Steps to perform during a reconfiguration. The resize is performed from X sources processes to Y targets.
In this research line are studied different strategies to perform the first three stages of malleability in order to improve the application execution time and/or the throughput of the system. To check the results, a synthetic and malleable emulator has been developed, which allows to check the different strategies while emulating real parallel applications. These are a few of the most relevant papers written by the group [1][2]
Following can be found a link to the GitLab project:
References
- (2022): A Survey on Malleability Solutions for High-Performance Distributed Computing. In: Applied Sciences, vol. 12, no. 10, 2022, ISSN: 2076-3417.
- (2023): Configurable synthetic application for studying malleability in HPC. In: Montella, Raffaele; Blas, Javier Garc’ıa; D’Agostino, Daniele (Ed.): 31st Euromicro International Conference on Parallel, Distributed and Network-Based Processing, PDP 2023, Naples, Italy, March 1-3, 2023, pp. 128–135, IEEE, 2023.
Fault Tolerance
PI: José M. Badía y Germán León.
Electronic devices, from large servers to embedded systems, can fail due to multiple factors, including voltage, temperature, obsolescence or radiation. Failures are especially important in large supercomputers that include many thousands of servers or embedded systems used in critical applications, such as health-related systems, satellites or driver assistance systems.
Detecting, correcting or mitigating such errors can have a major impact on economic and even human health and safety.
Commercial embedded systems including heterogeneous architectures are a very attractive alternative to dedicated radiation hardened systems, due to their low cost and high performance per watt.
In this line of research we study the behaviour of such embedded systems under radiation. This includes the CPU, GPU, memory or specific components for machine learning. We use fault injection and accelerated radiation techniques to study the behaviour of various applications, including linear algebra kernels or neural networks. We also develop and analyse fault protection techniques based on redundancy or algorithm adaptation.
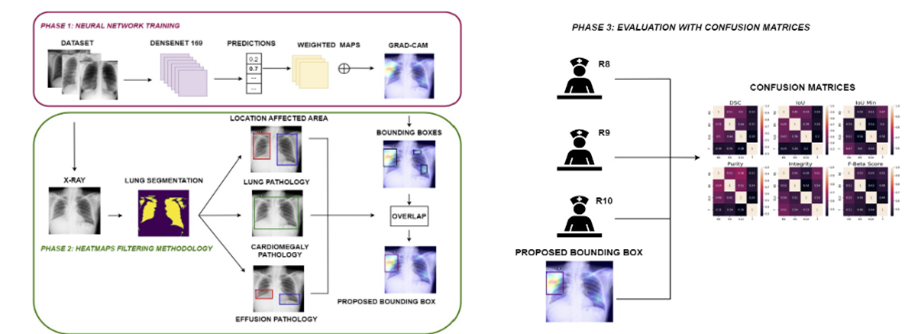
Deep Learning-based Medical Applications
PI: Sandra Catalán y Manuel F. Dolz.
Artificial intelligence, particularly deep learning, is revolutionizing the field of medicine, offering innovative solutions for diagnostics, treatments, and the management of medical data. Deep learning algorithms can process large volumes of medical data, including images, signals, and electronic health records, with unprecedented accuracy.
In this line of research, we explore the use of advanced deep learning techniques to develop medical applications that can improve patient care and optimize healthcare resources. This includes the analysis of medical images for early disease detection, clinical outcome prediction, personalized treatments, and the development of virtual assistants for medical support.
Our research focuses on several key aspects:
- Torax radiography: We use convolutional neural networks (CNNs) to analyze chest X-rays with the aim of detecting pulmonary diseases, including pneumonia, tuberculosis, and lung cancer.
- Retinography: We apply deep learning models to interpret retinal images, aiding in the early detection of ocular diseases such as diabetic retinopathy, glaucoma, and macular degeneration.
We utilize extensive datasets and collaborate with medical institutions to validate and refine our applications, ensuring their effectiveness and reliability in real clinical environments. Additionally, we work on the interpretability and explainability of deep learning models, ensuring that healthcare professionals can understand and trust the decisions generated by these systems.
Our ultimate goal is to integrate these technologies into the clinical workflow, enhancing the accuracy of diagnoses, the efficiency of treatments, and ultimately, the quality of life for patients.
Quantum circuits simulations
PI: José M. Badía y Maribel Castillo.
Quantum computers can have a huge social and economic impact in many areas, including cybersecurity, banking, pharmaceuticals and many others. Currently we have very few small and unreliable quantum computers. The development of new scalable simulators of quantum circuits on scalable classical computers is therefore fundamental for the advancement of quantum computing, both in terms of hardware improvement and in the design and implementation of new and better algorithms.
One of the main restrictions for the development of this type of simulators is the enormous spatial and temporal cost of the exponential increase in the size of the circuits with the number of cubits.
In this line of research, we use different techniques to efficiently simulate quantum circuits. These include representing the circuits using tensor networks or storing and handling them using alternative data structures to matrices, such as decision diagrams. In addition, we use parallel computing techniques to optimise both the temporal and spatial performance of the simulation.
Post-Quantum Cybersecurity for Federated Learning
PI: Sandra Catalán y Manuel F. Dolz.
Post-quantum cybersecurity and federated learning are two emerging fields at the intersection of computer science and cryptography, with significant potential to transform how sensitive information is protected and managed. With the advent of quantum computers, many current cryptographic methods will become vulnerable, necessitating the development of new security techniques. Simultaneously, federated learning allows training artificial intelligence models using distributed data, preserving user privacy.
In this line of research, we explore how to integrate and secure federated learning systems against quantum threats through post-quantum cybersecurity techniques. Our goal is to ensure the security and privacy of data throughout the entire learning process, from data collection to training and inference.
Our research focuses on several key aspects:
- Post-Quantum Cryptographic Algorithms: We develop and evaluate cryptographic algorithms resistant to quantum attacks to protect communication and data storage in federated learning environments.
- Protection Against Distributed Attacks: We analyze and develop mechanisms to safeguard federated learning systems against distributed attacks, such as data poisoning and inference attacks.
In this regard, an additional key is the usage of homomorphic encryption that allows mathematical operations to be performed in the encrypted domain that when decrypted matches the result of operations in the plain domain. The two allowed operations are addition and product.
Implementing these solutions requires a high level of complexity and significant computational resources. Therefore, we utilize high-performance computing (HPC) techniques to optimize the processing and security of federated learning models. We leverage advanced hardware and software architectures to ensure the efficiency and scalability of our solutions.
Our ultimate goal is to integrate these technologies into federated learning systems in a way that makes them resistant to quantum threats and capable of protecting the privacy and security of data at all stages of the process. With these innovations, we aim to set a new standard of security for the post-quantum era, preserving the trust and integrity of distributed artificial intelligence systems.